Grasping How it Works
The Different Types of Neural Network
Essentially, it consists of ANN, DNN, CNN, RNN, LLM, which are great in different aspects such image and speech recognition. However I was more intrigued with the process of how data is used or processed.
Vector Embeddings
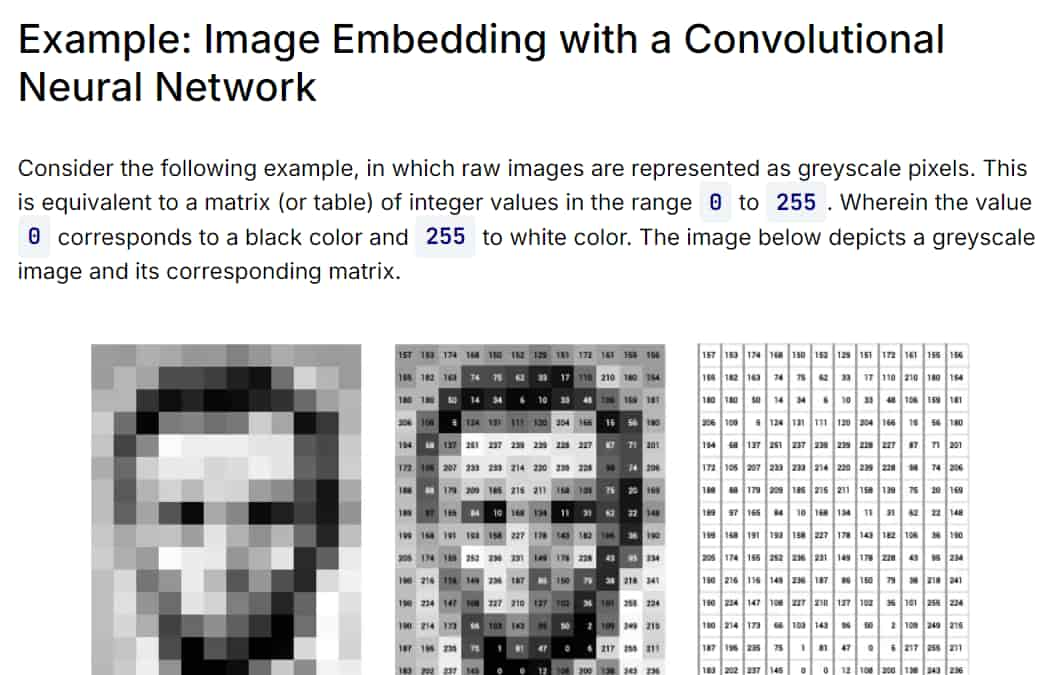
To put it in simpler terms, the data Convert words, sentences, images & etc into numbers. From my
understanding of the topic, embedding is a way to store data (images, Audio files, Text, Documents, etc)
with number arrays called vectors.
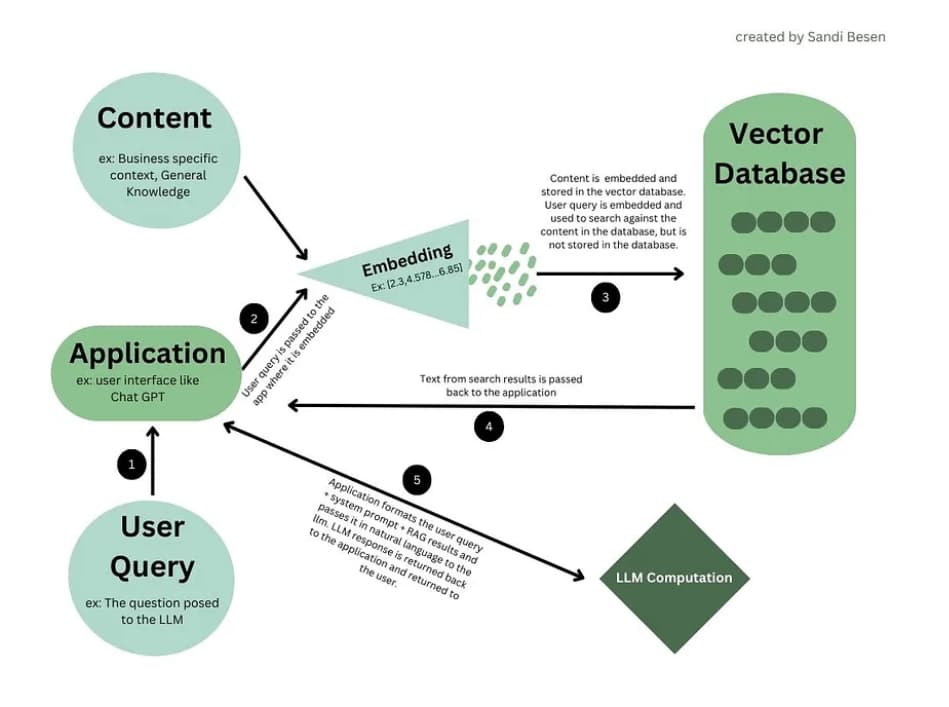
These vectors are a range of numbers which stored in a Vector Database.
Therefore when there is query/prompt, the prompt will be processed into embedding and goes through the
Vector Database, finding vectors related to the query, then a retrieval mechanism will pass the
information back. In simpler term, RAG is a method used to retrieve the most similar vector in the
Vector Database.
"Can we manipulate vector embeddings?"
Through the research, I was wondering if these values generated could be modified to manipulate the data.
"Data Poisoning?"
Another term which came up during my research, poisoning data with the example of adding noise to a spam filter training set, making the system misclassify legitimate emails as spam.
"Imperceptible Data"
Data becomes a item of transaction to training your models" if every training models requires a data - Human Data is the new currency?
My Understanding
From my understanding of the topic, embedding is a way to store data (images, Audio files, Text, Documents, etc) with number arrays called vectors. These vectors are a range of numbers which stored in a Vector Database. Therefore when there is query/prompt, the prompt will be processed into embedding and goes through the Vector Database, finding vectors related to the query, then a retrieval mechanism will pass the information back. In simpler term, RAG is a method used to retrieve the most similar vector in the Vector Database.
State of Research Pillars
At this rate, I feel like there was so many information and topics that branched that which was making me really confused with what to do and the direction that I’m moving towards with my research. The research seem to take on the technical side more than design which was starting to seem off the more I read.
However, after the consultation with Andreas, I was clearer with what I want to research as he helped to sort out my thoughts which was all over the place. The following will consist of the 3 pillars of research for my project.
"Oversaturation of AI"
Using speculative design to open the topic about the near future where a oversaturation of AI in the market and industry as the overarching theme. The topic can cover the trends and development over the years espscially with the AI boom.
"Data as Commodity"
How with the current issue of big companies hiding data information from the public and perhaps with the speculative approach to raise awareness about the power play of data usage and how opening the discussion about creating a democratic/safe environment for data usage? Maybe with the help of journalistic approach, how we do communicate that with a more visual approach?
"Non-Human Centered Designs"
We have always been designing human centered designs but in near future we might be dealing with non-human centered design which leads to AI-centered design. Hence, what do we know about human-centered design and the difference to non-human centered design. More readings about non-human-centered design?
Observations
Some Observations that I had relating to the topic of AI saturation includes the rise of marlet place for AI models such as CivitAI and HuggingFace itself.
As of current 11th September 2024, there’s a total number of 934,271 training models created and shared on Huggingface, varying from all the different functions.